I previously wrote that when Firefox receives a file whose media type is text/markdown, it prompts the user to download it, whereas other browsers display rendered results.
Now it is possible to upvote a proposal on connect.mozilla.org asking that Firefox renders Markdown by default.
Update: thanks to the very kind involvment of the widow of our wemaster, we could provide enough private information to Dreamhost, who finally accepted to reset the password and the MFA. We have recovered evrything! Many thanks to everybody who helped us!
Due to tragic circumstances, one association that I am part of, Sciencescope got locked out of its account at Dreamhost. Locked out, we can not pay the annual bill. Dreamhost contacted us about the payment, but will not let us recover the access to our account in order to pay. So they will soon close the account. Our website, mailing lists and archives, will be erased. We provided plenty of evidence that we are not scammers and that we are the legitimate owners of the account, but reviewing it is above the pay grade of the custommer support (I don't blame them) and I could not convince them to let somebody higher have a look at our case.
If you work at Dreamhost and want to keep us as custommers instead of kicking us like that, please ask the support service in charge of ticket 225948648 to send the recovery URL to the secondary email adddresses (the ones you used to contact us about the bill!) in addition to the primary one (which nobody will read anymore). You can encrypt it for my Debian Developer key 73471499CC60ED9EEE805946C5BD6C8F2295D502 if you worry it gets in wrong hands. If you still have doubts I am available for calls any time.
If you know somebody working at Dreamhost can you pass them the message? This would be a big, big, relief for our non-profit association.
When Firefox receives a file with media type text/markdown, it prompts the user to download it, while other browsers display it as plain text. In the ticket 1319262, it is proposed to display Markdown files by default, but there needs a patch…
A discussion on the debian-project mailing list caught my attention to an Italian word meaning something like “would you be so kind to please go somewhere else?”, but in a more direct and vulgar manner. I then used http://codesearch.debian.net to study its usage more in detail.
I found it in:
- the source code of XEmacs;
- a list of bad words to filter conversations in BZflag;
- the random sentence generator PolyGen;
- the source code of the board game Tagua;
- a database of offensive fortunes for the educative platform WIMS;
- the crossword game parolottero;
- a database of offensive fortunes for login screens and email signatures;
- a list of (too) frequent passwords;
- a source code comment aimed at somebody called Wolf;
- a collection of rude gestures in the xwrists package.
That was a refreshing and pleasant recreation in the Debian package universe.
At the beginning of this year I updated a hundred of media
types associated with file name
extensions in the file called /etc/mime.types, distributed by the
media-types package. Most
changes
are additions originating from recent submissions to the
IANA. Amon the themes that
caught my attention, there are telecommunications, computer security,
commerce, healthcare and industrial automation. The vast majority of the
update come from western provenance. Did the rest of the World decide to
move ahead without us?
Via my work on the media-types package,
I wanted to know which packages were using the media type
application/x-xcf,
which apparently is not correct (#991158).
The https://codesearch.debian.net site gives the answer. (Thanks!)
Moreover, one can create a user
key, for command-line remote
access; here is an example below (the file dcs-apikeyHeader-plessy.txt
contains x-dcs-apikey: followed by my access key).
curl -X GET "https://codesearch.debian.net/api/v1/searchperpackage?query=application/x-xcf&match_mode=literal" -H @dcs-apikeyHeader-plessy.txt > result.json
The result is serialised in JSON. Here is how I transformed it to make a
list of email addresses that I could easily paste in mutt.
cat result.json |
jq --raw-output '.[]."package"' |
dd-list --stdin |
sed -e '/^ /d' -e '/^$/'d -e 's/$/,/' -e 's/^/ /'
I am trying R 4.1 in a schroot experimental container, while waiting that Bullseye's release will allow the package to be uploaded to Sid and the needed dependencies to be recompiled.
The schroot:
sudo debootstrap sid /srv/chroot/r-4.1 http://deb.debian.org/debian
sudo vi /etc/schroot/chroot.d/r-4.1
# Edit it to have something like
[r-4.1]
description=R 4.1 (experimental)
type=directory
directory=/srv/chroot/r-4.1
users= # Here put your username
root-groups=root
profile=desktop
personality=linux
preserve-environment=true
sudo schroot -c r-4.1
vi /etc/apt/sources.list # To add the experimental distribution
apt update
apt install sudo vim wget
exit
Installation of R:
schroot -c r-4.1
sudo apt install r-base/experimental -texperimental
sudo apt install -texperimental pandoc libxml2-dev libcurl4-openssl-dev git libssl-dev texlive
And RStudio (preview version needed)
wget https://s3.amazonaws.com/rstudio-ide-build/desktop/bionic/amd64/rstudio-1.4.1714-amd64.deb
sudo apt install libnss3 libasound2
sudo dpkg -i rstudio-1.4.1714-amd64.deb
sudo apt -f install -texperimental
Debian Bullseye will provide the command /usr/bin/open for your greatest
comfort at the command line. On a system with a graphical desktop
environment, the command should have a similar result as when opening a
document from a mouse-and-click file browser.
Technically, /usr/bin/open is a symbolic link managed by
update-alternatives to
point towards xdg-open if
available and otherwise
run-mailcap.
A couple of days ago I wrote on debian-vote@ that a junior analyst could study the tally sheets of our general resolutions and find the cracks in our community.
In the end, with a quite naïve approach and a time budget of a few hours, I did not manage anything of interest. The figure below shows one circle per voter and my position as a red dot. The circles are spaces according to the similarity of the vote profiles after I concatenated the results of all GRs until 2010.
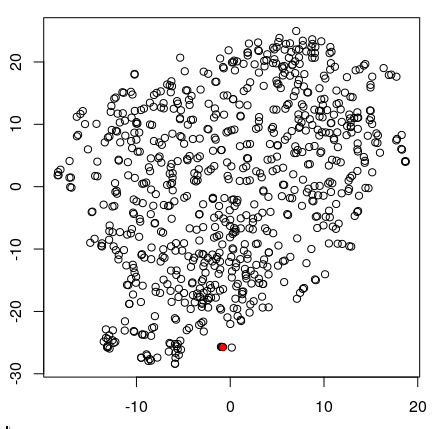
So if there is something to extract from these data, it will need a more expert analyst… This said, I think that our future votes should all be anonymous, and that we should stop distributing that kind of data.
Many quickly reacted to the return of rms to the FSF and asked that he leaves again; some also asked for the whole board of directors to resign and some not. Meanwhile, Debian discusses a general resolution on that matter. Maybe it was not the original intent, but in practice the object of the GR is about FSF's board of directors. Perhaps we will have the result after rms resigns? Like many GRs, it will divide Debian and leave scars, at least a tally sheet of who voted what, and who voted like whom.
I think that most other organisations did not go through a process as plenary and collegial, but also heavy and cleaving, to decide which way to go.
What if our two DPL candidates would issue a statement that, if elected, they would refuse to fund events linked to the FSF until rms quits again (and also the directors, if that is what the DPL candidate wishes to propose). This would let Debian be part of the wave of reaction on time, and maybe allow us to cancel this GR?